
前言
有抓取網站資料的需求是因為我們的Shopline網站即將到期
由於沒有打算進行續約,所以要確認一下該網站目前有多少頁面
後續將網域取回來後才有辦法設定不要讓Google報很多404的錯誤
首先我們確認了該網站的sitemap網址 : https://www.colorpen.com.tw/sitemap.xml
1.提供sitemap連結給chatGPT

提供連結給chatgpt讓AI自動抓取內容,不過會遇到一個問題
當資料過大時會導致遇到chatGPT的限制導致無法全部讀取

這時候就聽從chatGPT的建議來使用網頁爬蟲腳本
並直接請chatGPT提供python的腳本代碼
2.請求chatGPT提供python腳本
既然無法讓chatGPT抓取全部的資料,那就請chatGPT告訴我們要如何抓取
將chatGPT提供的程式輸入到空白記事本,並將副檔名改為.py就是python的執行檔了
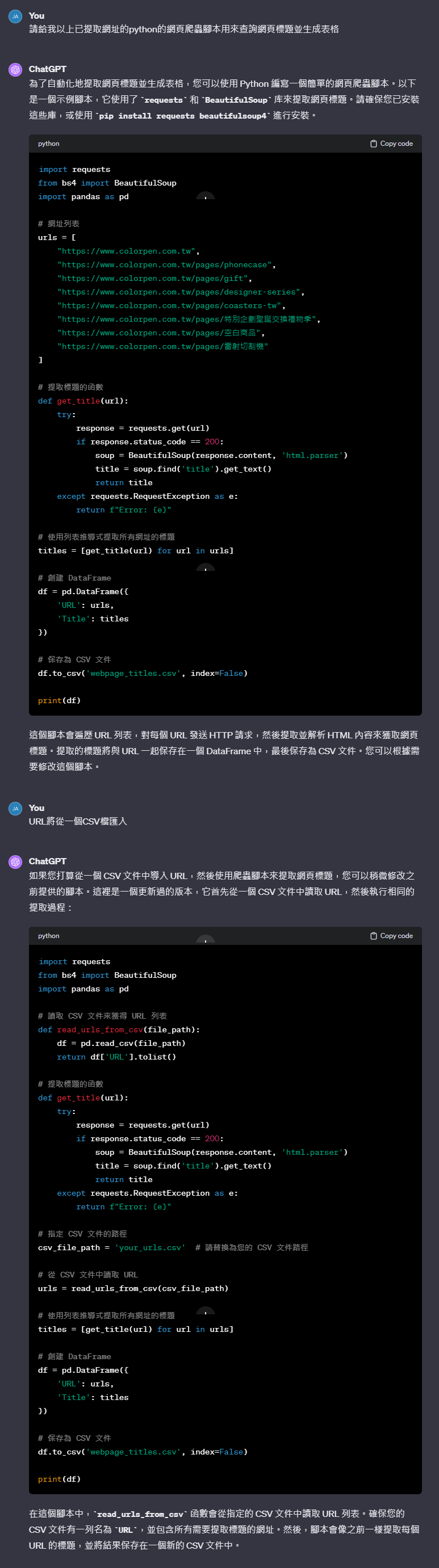
chatGPT提供的python代碼
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 讀取 CSV 文件來獲得 URL 列表
def read_urls_from_csv(file_path):
df = pd.read_csv(file_path)
return df['URL'].tolist()
# 提取標題的函數
def get_title(url):
try:
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'html.parser')
title = soup.find('title').get_text()
return title
except requests.RequestException as e:
return f"Error: {e}"
# 指定 CSV 文件的路徑
csv_file_path = 'your_urls.csv' # 請替換為您的 CSV 文件路徑
# 從 CSV 文件中讀取 URL
urls = read_urls_from_csv(csv_file_path)
# 使用列表推導式提取所有網址的標題
titles = [get_title(url) for url in urls]
# 創建 DataFrame
df = pd.DataFrame({
'URL': urls,
'Title': titles
})
# 保存為 CSV 文件
df.to_csv('webpage_titles.csv', index=False)
print(df)
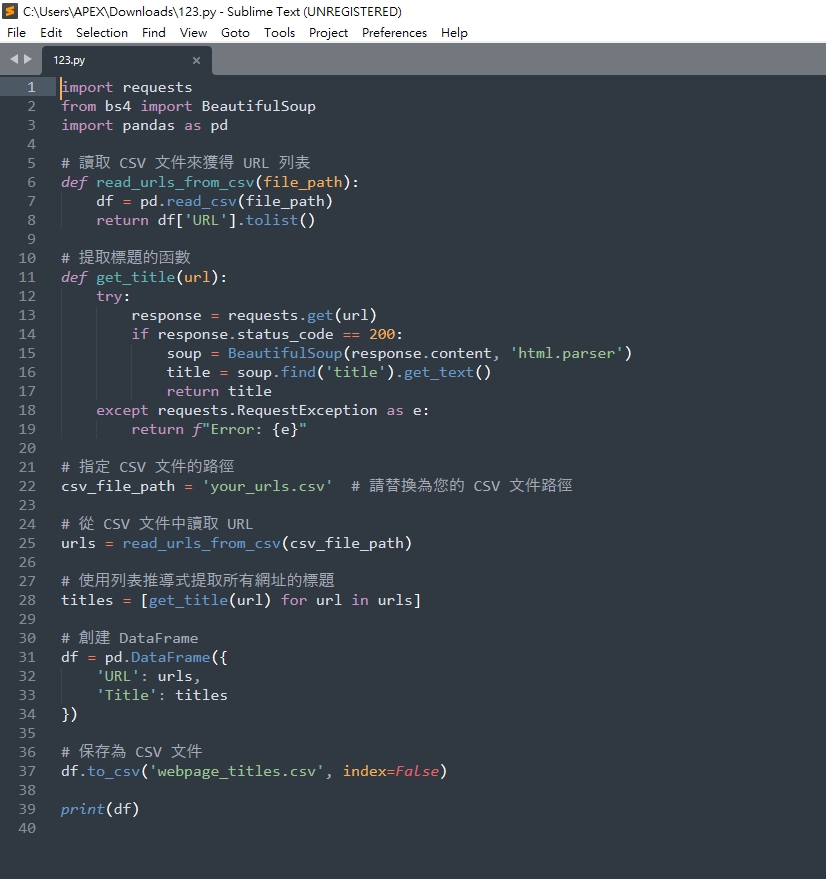
調整後的python代碼
由於我們是要提供.csv讓python去抓取
所以要將.csv的檔案路徑提供給程式
chatGPT也很好心的說明有哪一些地方要進行調整
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 讀取 CSV 文件來獲得 URL 列表
def read_urls_from_csv(file_path):
df = pd.read_csv(file_path)
return df['URL'].tolist()
# 提取標題的函數
def get_title(url):
try:
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'html.parser')
title = soup.find('title').get_text()
return title
except requests.RequestException as e:
return f"Error: {e}"
# 指定 CSV 文件的路徑
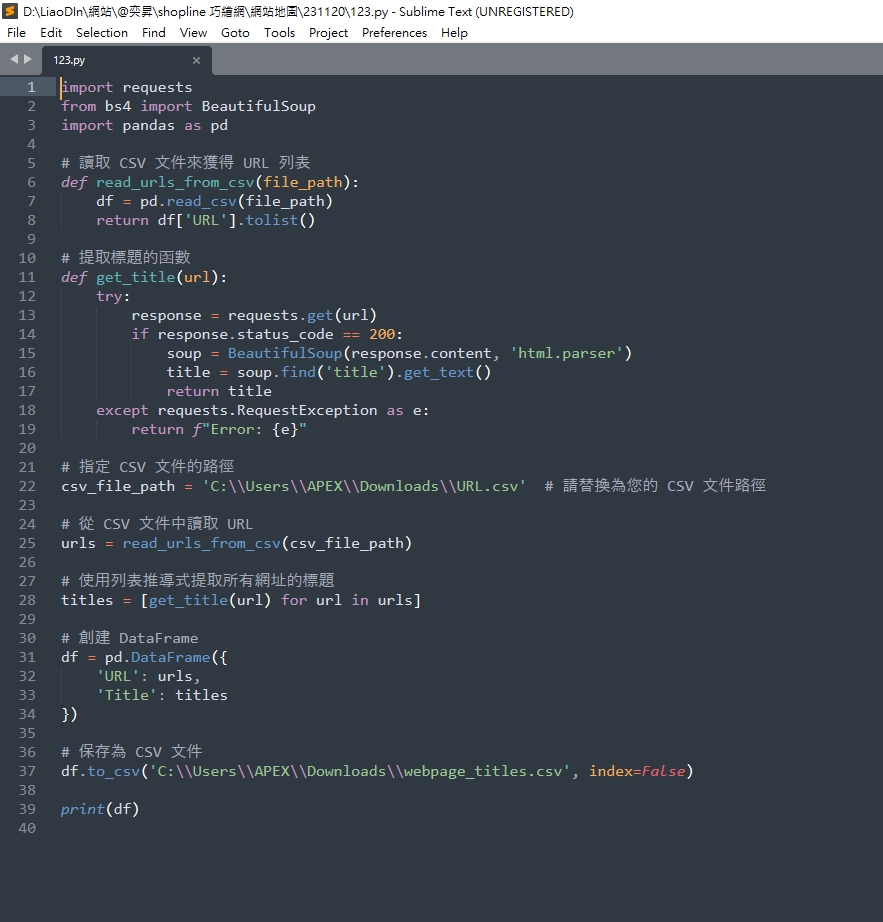
csv_file_path = 'C:\\Users\\APEX\\Downloads\\URL.csv' # 請替換為您的 CSV 文件路徑
# 從 CSV 文件中讀取 URL
urls = read_urls_from_csv(csv_file_path)
# 使用列表推導式提取所有網址的標題
titles = [get_title(url) for url in urls]
# 創建 DataFrame
df = pd.DataFrame({
'URL': urls,
'Title': titles
})
# 保存為 CSV 文件
df.to_csv('C:\\Users\\APEX\\Downloads\\webpage_titles.csv', index=False)
print(df)
3.安裝與執行python
當python程式撰寫好了,我們選擇直接使用Windows 命令提示字元運行
要執行python應用程式時,首先要到python官網下載才能進行使用
本次下載3.12的python版本
下載完成後,點擊windows+R並輸入CMD開啟命令提示字元運行
由於python的程式執行檔取名為123.py,並放在C槽的Downloads資料夾
我們要將.csv檔案放在程式內的指定路徑,以及讓命令提是字元進入Downloads資料夾
只要輸入 cd Downloads,就能進入Downloads資料夾
接下來輸入 py 123.py 就可以開始執行此python的應用程式了
4.python除錯過程
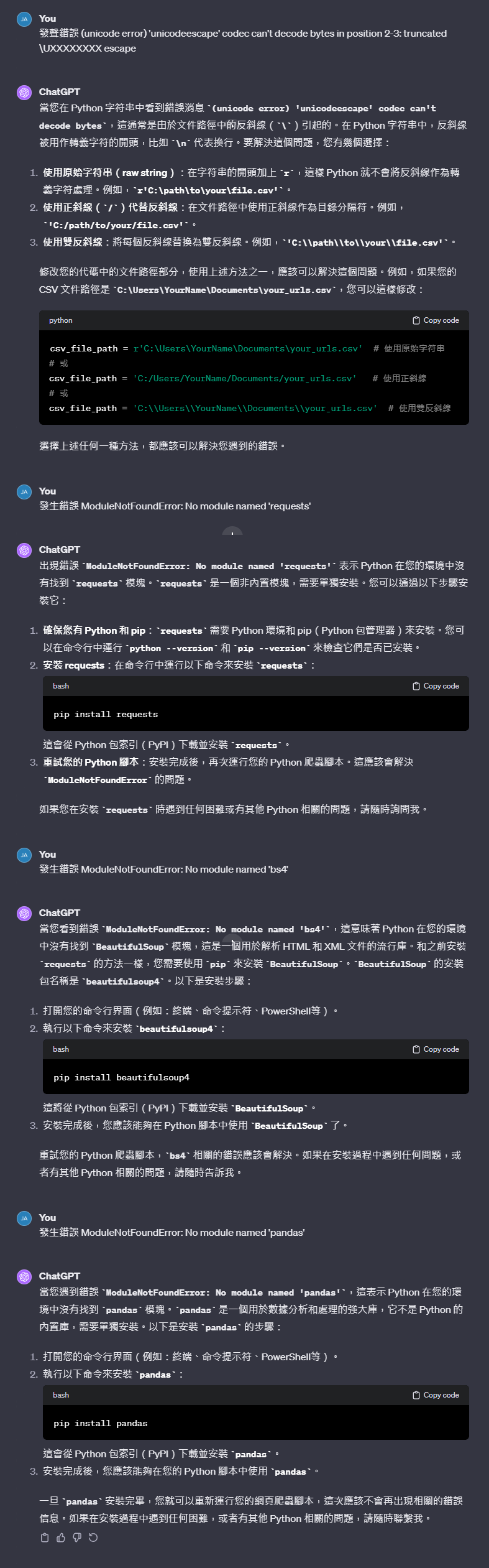
由於我並沒有執行python的經驗
直接執行程式後通常會遇到一些錯誤需要排除
我們這邊就直接將錯誤訊息發送給chatGPT來進行修正
第一次、遇到的是斜線問題
第二~四次、都是未安裝python的模塊
全部按照chatGPT的說明進行安裝就可以成功運行了
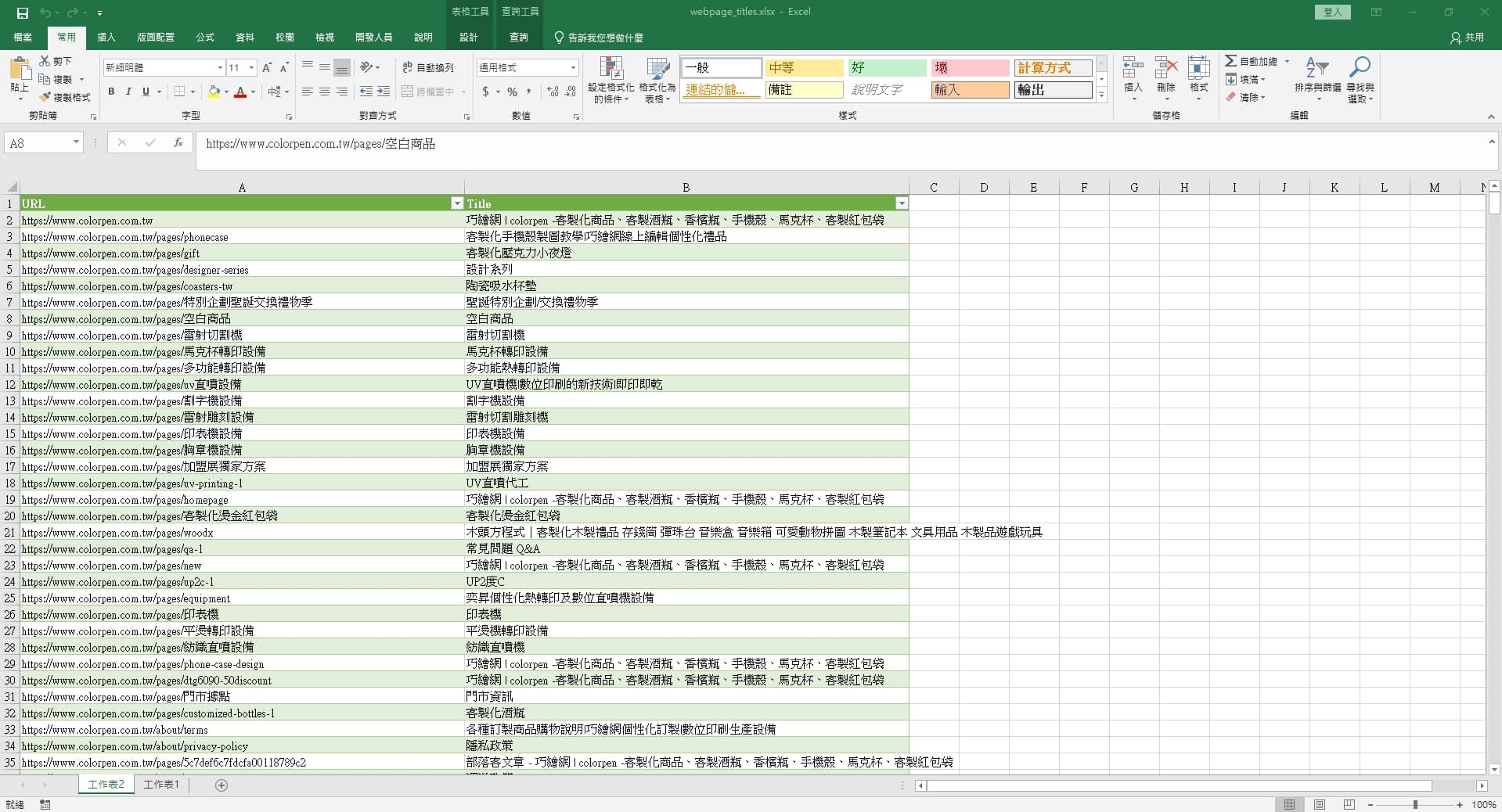
因為這次抓取的連結有800多個,程式也運行了一段時間
第一次運行會因為等的時間較久,不確定有沒有成功
可以將.csv檔案內的連結改為2個,讓程式跑跑看
確認成功後,再進行完整的資料抓取
另外抓取完成後,如果遇到亂碼可以參考文章:Excel .csv開啟亂碼解決